PYTHON IN LOCAL
Install Python in Local
https://www.python.org/ 에서 각자의 PC에 최신 Python 버전을 설치합니다.
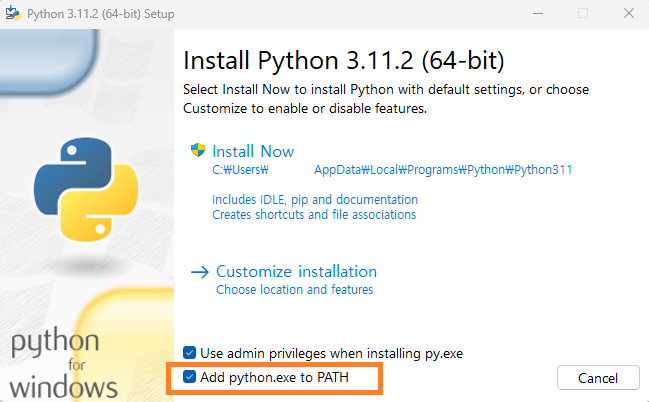
윈도우에서는 설치 시 아래와 같이 "Add python.exe to PATH" 옵션을 활성화해줍니다.
PC의 터미널(윈도우의 경우 cmd, 맥의 경우 terminal 실행)에서 python --version을 입력했을 때 설치한 버전이 예컨대 Python 3.11.2와 같은 식으로 뜨면 잘 설치된 것입니다.
Ways to Use in Local
(1) 대화식 인터프리터
Python은 스크립트 언어이기 때문에 굳이 하나의 파일을 통째로 실행시킬 필요가 없습니다. 하나의 런타임이 실행되는 동안 사용자가 원하는 만큼 한줄 한줄씩 코드를 입력하고 실행시켜도 되죠.
운영체제의 터미널을 사용해 한줄씩 파이썬 코드를 입력하고 실행시킬 수 있습니다. 참고로 터미널처럼 한줄씩 운영체제에 명령을 전달해 처리하는 시스템을 Command Line Interface(CLI)라고 부릅니다.
터미널에서 python을 입력하면, Python 코드를 입력할 수 있는 상태로 화면이 바뀝니다. 이 순간 하나의 python 런타임이 생성되었습니다. 한줄씩 Python 코드를 입력해 이 런타임과 직접 상호작용할 수 있습니다.
print("Hello World")를 입력하면, "Hello World"라는 문자열이 출력(print)됩니다.
a=2를 입력하면, 런타임 내에서 값 2를 갖는 변수 a가 선언됩니다. 별도의 출력 명령은 없기 때문에 상태창에 어떤 출력이 표시되지는 않습니다.
이제 b=3을 입력하고, 이어서 print(a+b)를 입력하면 5가 출력됩니다.
터미널에서 생성된 Python 런타임을 종료하고 싶다면 exit() 구문을 입력하면 됩니다. 런타임이 종료되고, 처음 터미널을 켰을 때의 화면으로 돌아갑니다.
우리는 방금 컴퓨터에 설치된 파이썬을 대화식 인터프리터 방식으로 사용했습니다. 만일 컴파일 언어였다면 이렇게 한줄씩 상호작용하는 식으로 사용할 수는 없었을 것입니다. 컴파일 언어로 작성된 파일을 런타임에서 실행시키려면 미리 파일 전체를 처음부터 끝까지 컴파일 해야하니까요.
(2) 스크립트 파일 작성하고 실행하기
간단한 구문은 터미널에서 직접 실행할 수 있지만 큰 규모의 코드를 입력하기는 어렵습니다. 무엇보다 프로그램 코드는 보통 자동화되야 합니다: 즉 미리 만들어진 코드를 실행만 시키면 의도된대로 동작해야 합니다. 하지만 터미널에 한줄씩 직접 입력해서는 자동화할 수가 없죠.
Python을 사용하는 보다 일반적인 방법은 미리 Python 스크립트 파일을 작성하고, python 명령어를 통해 이 파일을 실행하는 것입니다. Python 파일은 보통 .py 확장자를 붙여줍니다.
한번 하나의 스크립트 파일을 작성하고 실행시켜 봅시다. 먼저 스크립트 파일을 저장할 임의의 폴더를 만듭니다. 그리고 다시 터미널을 열고 cd 명령어를 이용해 해당 폴더의 디렉토리로 이동합니다.
그리고 해당 폴더에 운영체제의 기본 텍스트 편집기를 이용해 임의의 .py 파일을 만들어 봅시다.
예컨대
a = 2
b = 3
add = a+b
print(f"a+b={add}")
라는 코드를 add.py라는 이름으로 저장해 보겠습니다.
이제 터미널에서 python add.py를 실행해보면, 터미널에 a+b=5라는 결과가 출력됩니다.
운영체제 내에서 하나의 python 런타임이 만들어지고, 그 런타임이 add.py 스크립트 파일을 읽고 실행시킨 것입니다. 실행이 종료되면 런타임도 종료됩니다. 이처럼 python + (파일 이름)을 입력하면 해당 파일에 적힌 파이썬 코드를 실행시킬 수 있습니다.
방금 우리는 파일 하나짜리의 Python 프로그램을 만들고 이를 실행시킨 것입니다.
컴파일 언어라는 파일을 런타임에 실행시키기 전에 먼저 컴파일 하는 과정을 거쳐야 하지만, 우리 Python은 스크립트 언어이기 때문에 컴파일 과정 없이 바로 실행됩니다.
IDE / 에디터 사용하기
그런데 Python 프로그램을 만들 때마다 이런 식으로 작업하는 건 여간 번거로운 작업이 아닙니다. 때문에 대부분의 경우 파일 작성을 돕는 IDE(통합개발환경)이나 코딩을 돕기 위해 설계된 텍스트 편집기 소프트웨어를 사용하게 됩니다.
Python의 경우, Python을 위해 제작된 IDE인 PyCharm 또는 Python뿐 아닌 여러 언어를 사용할 수 있는 편집기인 Visual Studio Code(vscode)를 많이 사용합니다.
이런 소프트웨어들은 처음엔 사용법이 낯설 수 있지만, 익숙해지게 되면 매우 유용한 도구가 됩니다.
(3) 주피터 노트북
주피터 노트북을 사용하는 일은 앞선 방법들에 비해 특수한 케이스입니다. 주피터 노트북이라는 하나의 프로그램을 별도로 설치한 후, 이 프로그램 안에서 파이썬을 이용하는 일이니까요.
주피터 노트북은 하나의 주피터 노트북 파일(보통 .ipynb 확장자로 끝나는)을 실행시키는 런타임을 만들고, 그 런타임 내에서 마치 대화식 인터프리터처럼 계속 구문을 추가하면서 작업할 수 있도록 지원해주는 일종의 플랫폼입니다. 여러 데이터를 불러오고 조금씩 읽고 수정하면서 작업하기 매우 편리합니다.
역시 컴파일 언어가 아닌 스크립트 언어이기 때문에 가능한 일입니다.
노트북 파일을 닫거나 주피터 노트북 사용을 종료하면 런타임도 종료됩니다. 또 각각의 노트북 파일들은 서로 독립된 런타임을 갖습니다.
로컬 PC에 주피터 노트북을 설치하고 사용하는 방법은 조금 뒤에 다시 살펴봅시다.
그럼 Colab은 뭘까
코랩의 생김새나 작동방식은 주피터 노트북과 다를 바가 없습니다. 다만 코랩은 구글이 제공하는 네트워크 너머에 있는 원격 서버에서 주피터 노트북(같은 것)을 실행하는 방식입니다. 우리가 브라우저에서 코드를 입력하면, 코드 텍스트 데이터는 네트워크를 따라 (바다 건너?) 어딘가에서 실제 작동 중인 원격 서버의 파이썬 런타임에 전달되고, 여기서 실제로 코드가 실행된 후 결과값이 출력되면 다시 네트워크를 타고 우리가 사용하는 브라우저에 전달되어 화면에 표시됩니다.
네트워크를 통해 데이터가 오가기 때문에 로컬 PC에서 주피터 노트북을 사용할 때보다 속도가 느릴 수 있지만, 구글 드라이브에서 바로 사용할 수 있고 공유할 수 있다는 점이 장점이죠. 또 로컬 PC의 경우 운영체제에 따른 차이 등 PC 설정에 따라 신경써야 할 점이 있지만 코랩을 사용하면 그런 점이 없다는 것도 장점입니다. 참고로 Colab의 원격 서버가 사용하는 운영체제는 Linux 계열입니다. 코랩은 어느 정도 원격 서버 자체와도 상호작용할 수 있도록 지원하는데, 우리는 코랩을 통해 구글이 제공하는 하나의 리눅스 원격 서버를 사용하는 셈입니다.
인터넷을 연결하고 코랩을 사용하는 일은 magical 하지만, 그 모든 것이 어딘가에 실재하는 물리적 컴퓨터 공간에서 발생하고 있는 일임을 늘 명심합시다.
Files Relations
Module & NameSpace
코랩에서 __name__ 변수를 출력해보면 __main__이라는 값이 출력될 것입니다.
이번엔 로컬 PC의 디렉토리에서 새로운 스크립트 파일을 만들어 실행시켜 봅시다. 파일 이름을 whatsurname.py이라고 하고,
print(__name__)
와 같이 작성한 후 터미널에서 python whatsurname.py를 실행합니다. (파일이 있는 디렉토리로 이동한 후 실행하세요! 또는 파일명 대신 파일 경로를 적어주세요.)
역시 __main__이 출력될 것입니다.
하나의 파이썬 파일은 하나의 "모듈"을 이룹니다. 그냥 파일 하나가 모듈 하나라고 생각하면 됩니다. 그리고 각각의 모듈은 자기만의 namespace를 가집니다. namespace라는 말이 조금 낯설 수도 있지만, 뭐, 각자 독립된 경계를 갖는 것이라고 직관적으로 생각하면 됩니다. 별도의 namespace는 별도의 변수명 체계를 가지고 있습니다. 같은 변수명이라도 서로 다른 namespace에서 선언된 것이라면 당연히 서로 상관 없는 변수입니다. 예컨대 add1.py에서 선언된 a=10과 add2.py에 선언된 a=20 사이에는 아무런 관련도 없습니다.
그리고 이 namespace가 갖는 이름이 있습니다. 즉 __name__ 변수입니다. 이때 "최상위"의 namespace의 __name__ 변수는 __main__라는 str 값을 갖습니다.
최상위 namespace는 python 런타임이 가장 처음 실행시키는 모듈(=파일)을 뜻합니다. 그럼 그렇지 않은 파일이 있다는 걸까요? 네 그렇습니다.
새로운 스크립트 파일을 만들어 봅시다. 2개를 만들겠습니다.
하나는 calculate.py라는 이름으로,
HUNDRED: int = 100
THOUSAND: int = 1_000
def add(x: int, y: int) -> int:
return x+y
def subtract(x: int, y: int) -> int:
return x-y
def print_name():
print(__name__)
와 같이 작성합니다.
다른 하나는 run.py라는 이름으로,
import calculate
# from calculate import *
from calculate import HUNDRED, THOUSAND, add, subtract, print_name
if __name__=="__main__":
print("2+3:", add(2, 3))
print("3-2:", subtract(3, 2))
print("100+1000:", add(HUNDRED, THOUSAND))
print("type of calculate:", type(calculate))
print_name()
와 같이 작성합니다.
이제 python run.py를 실행시켜 봅시다.
2+3: 5
3-2: 1
100+1000: 1100
type of calculate: <class 'module'>
calculate
이와 같은 결과가 출력되나요?
이 두 파일을 하나씩 뜯어 봅시다. 먼저 run.py에서 우리는 calculate 모듈을 import 해왔습니다. 또 from calculate import ... 구문을 통해, calculate 모듈(파일) 안에 정의되어 있는 HUNDRED, THOUSAND 변수와, add, subtract, 그리고 print_name 함수를 import 해왔습니다.
(import 된 변수들은 새로운 데이터로 복제되어 run 모듈 안에서 새롭게 선언된 것입니다. calculate 모듈 안에 있던 변수들과는 메모리상 전혀 별개입니다!)
import 구문에 이어서, if __name__=="__main__": 조건문이 나옵니다. 앞서 우리는 최상위 모듈이 __main__을 namespace로 갖는다는 사실을 확인했습니다. 이 조건문은 따라서 최상위 모듈일 때만 다음 구문을 실행시키라는 명령이기도 합니다. 실행 프로그램의 최상위 모듈을 작성할 때 거의 항상 사용하는 구문입니다.
조건 블록 안에서 여러 구문을 실행시키고 있습니다. calulate 모듈에서 가져온 add 같은 함수들, 또 Hundred 같은 변수들이 아주 잘 사용되고 있네요.
마지막에서 두번째 줄, type(calculate)를 출력해보면 <class 'module'>이 출력되었습니다. 첫번째 줄에서 import 해온 calculate 객체의 type이 모듈이라는 뜻입니다. 각각의 파일이 각각의 모듈이라고 이미 얘기했죠. 보통 외부 파일을 import하는 상황에서 파일보다는 "모듈"이라는 용어를 많이 씁니다.
마지막으로 print_name()을 실행한 결과 calculate가 출력됩니다. 이 함수는 calculate.py 내부에서 해당 모듈의 namespace를 출력하는 함수였죠. 최상위 모듈이 아닌 모듈의 경우 파일 이름이 출력된다는 사실을 알 수 있습니다.
built-in modules
python에서 import time이나 import random을 실행하면 해당 모듈들이 바로 import됩니다. 이런 모듈들은 python이 설치될 때 함께 설치되어 온 built-in module들입니다. 아주 자주 사용되는 기본적인 용도를 가진 모듈들입니다.
system path
우리가 import calculate나 import time을 실행했을 때, 이 모듈들은 어떻게 읽히는 걸까요? 한번 코랩이나 스크립트 파일에서 다음 구문을 출력해봅시다.
import sys # `sys`도 built-in module입니다.
print(sys.path)
이러면 개별 환경마다 구체적인 내용은 다르지만,
['', 'C:\\Python312\\Lib', 'C:\\Python312\\Lib\site-packages', ... ]
같은 여러 경로의 리스트를 볼 수 있습니다.
이번엔 다음을 출력해봅시다:
import os # `os`도 built-in module입니다.
print(os.__file__)
os 모듈이 설치되어 있는 경로가 출력됩니다. 이 경로, 앞서 출력한 sys.path 가운데 있지 않나요?
sys.path가 보여주는 시스템 경로들은 외부 모듈을 불러오는 후보 경로들의 리스트입니다. 이 가운데는 built-in 모듈들이 설치되어 있는 경로도 있고, 우리가 Python을 사용하면서 필요에 의해 추가한 모듈들이 설치된 경로도 있고, 또 ''라고 되어 있는, 현재 파일이 존재하는 디렉토리도 있습니다. import something을 실행한다면, 이 경로들 가운데 something이라는 이름의 모듈이 있다면 불러오게 되고, 아니면 오류가 반환됩니다.
때론 sys.path.append 메소드를 이용해 직접 커스텀 경로를 추가하기도 합니다.
Packages
그리고 '패키지'가 있습니다. 사실 '모듈'과 '패키지'는 비슷한 용법으로 많이 사용됩니다. 다만 엄밀히 말하면 '패키지'는 여러 모듈들의 묶음읍니다. 앞서 본 os나 sys 같은 built-in 모듈들도, 또 앞으로 많이 볼 numpy나 pandas 같은 모듈들도 다 패키지입니다.
패키지들은 직접 실행되는 실행 프로그램일 수도 있지만, 많은 경우 개별 실행프로그램에 import 되어 사용되는 라이브러리 프로그램입니다.
우리가 직접 패키지를 만들고 사용할 수도 있고, 또 인터넷을 통해 배포할 수도 있습니다. 하지만 일단은 넘어갑시다.
pip install
os나 sys와 달리 numpy, pandas 등은 외부 패키지입니다. Python을 설치할 때 같이 설치된 builtin 패키지가 아니라, 누군가가 직접 만들어서 인터넷을 통해 배포한 패키지인 것입니다. Python 패키지를 관리하는 명령어는 pip입니다. 만일 터미널에서 pip list를 입력하면, 현재의 파이썬 시스템에 설치된 패키지 리스트가 나타납니다. 또 pip install numpy와 같이, intall + 패키지 이름을 입력하면, 해당 패키지의 이름이 인터넷 네트워크를 통해 로컬 파이썬 시스템에 설치됩니다.
pip는 어디서 외부 패키지를 가져오는 것일가요? 이곳에 전세계의 사람들이 직접 만든 패키지를 배포하고, pip 명령어는 패키지 이름을 조회하여 가져옵니다. 저 사이트에서 numpy이나 pandas같은 유명한 패키지 이름들을 검색해 보세요.
앗, 그런데 코랩에서는 pip install numpy를 할 필요 없이, 바로 import numpy가 가능했습니다. 그건 그냥 구글이 코랩이 작동하는 시스템에 자주 쓰는 패키지들을 미리 설치해뒀기 때문입니다.
그리고 우리가 데이터 분석을 할 때 많이 쓰는 주피터 노트북도 pip를 통해 배포되고 설치되는 프로그램입니다. pip install jupyter notebook을 통해 설치하고 바로 사용할 수 있죠. 이때 주피터 노트북은 numpy나 pandas와 달리 라이브러리 프로그램이 아니라 그 자체로 컴퓨터에서 실행되는 실행 프로그램입니다.
Virtual Environment
Python을 로컬 PC에 설치 후 바로 사용해도 되지만, Virtual Environment, 즉 가상환경을 설정하고 사용하라는 권고가 많습니다.
우리가 운영체제의 터미널에서 바로 python을 실행시키면, 단 하나의 Python 버전 및 패키지 시스템만 사용할 수 있습니다. 하지만 가상환경을 만들어 사용하면, 각각의 가상환경마다 서로 다른 Python 버전을 설정할 수 있고, 서로 다른 패키지 환경을 구성할 수 있습니다.
여러 종류의 작업을 하다보면, 외부 패키지들이 서로 충돌하는 경우가 생길 수 있습니다. 또는 설치된 파이썬 버전과 충돌할 수도 있습니다. 이런 경우 서로 충돌하지 않는 패키지와 파이썬 버전끼리 별도의 가상환경을 구성하고 관리하면 좋습니다.
주피터 노트북도 기왕이면 가상환경에 설치해 사용해봅시다.
venv
가상환경 만들기:
-
윈도우:
python -m venv my_venv
-
mac:
python3 -m venv my_venv
설치 후 실행하기:
-
윈도우:
my_venv\Scripts\activate
-
mac:
source my_venv/bin/activate
가상환경을 실행한 상태에서 예컨대 pip install numpy를 실행하면, 이 가상환경에 별도의 numpy 패키지가 설치됩니다.
가상환경을 실행한 상태에서 어떤 스크립트 파일을 실행하면, 그 스크립트 파일은 해당 가상환경의 시스템 경로로부터 필요한 패키지들을 import해옵니다.
가상환경에 jupyter notebook 설치하기
-
가상환경 실행 후,
-
pip install jupyter notebook -
해당 가상환경에서 주피터 노트북을 사용할 때는,
-
가상환경 실행 후,
-
jupyter notebook- 이후 기본 브라우저에 주피터 노트북 자동으로 뜸
Anaconda는 뭐지?
처음 주피터 노트북을 사용할 때 "ananconda"라는 말을 많이 들어보셨을 것입니다. 아나콘다는 데이터 분석에 유용한 패키지들을 한데 묶어서 관리하도록 지원하는 하나의 프로그램이면서, 그 자체로 별도의 파이썬 가상환경이기도 합니다. anaconda를 설치하게 되면 여러 패키지들이 같이 설치되는 경우가 많기 때문에, anaconda 가상환경 내에서 주피터 노트북으로 작업하기 편리한 이점이 있어 많이 사용하곤 합니다.
로컬 PC에서 주피터 노트북으로 데이터 분석을 할 때 anaconda를 사용할지, 아니면 처음부터 venv 명령어로 직접 가상환경을 만들고 자체적으로 패키지를 관리할지는 정답이 없는 선택의 문제입니다.
다만 다음 몇 가지를 고려했을 때, 직접 가상환경을 만들고 자체적으로 관리하는 편을 추천합니다.
- 처음부터 anaconda를 사용하게 되면 python의 가상환경 및 패키지 관리가 magical하게 처리되기 때문에 실제 로직을 체감하기 어려움
- 많이 개선되고 있지만, anaocada를 이용한 패키지 설치 속도는 다소 느린 편
- anaconda가 제공하는 자체 생태계의 이점이 있지만, 반드시 anaconda를 써야만 할 만큼 절대적이지 않음
Practice
-
로컬 PC에 파이썬을 설치하고,
-
venv 명령어로 가상환경을 만들고, 해당 가상환경을 실행한 상태에서,
-
pip명령어로 주피터 노트북을 설치하고 실행시켜 작업해보기 -
어떤 폴더에
utils.py와run.py파일을 만들고, 각각
# utils.py
def add(a, b):
return a+b
# run.py
from utils import add
if __name__=="__main__":
print(f"2+3={add(2, 3)}")
와 같이 작성한 후, run.py를 실행시켜 보기