Day1: 1. "Active Py"
강연의 제목을 "ActivePy"라고 지었습니다. 어떤 의미일까요? 중요하지 않습니다. 그냥 이렇게 이름을 지었을 뿐입니다.
데이터 분석을 배우다 보면, 혹은 Python 같은 프로그래밍 언어를 배우다보면 새로운 개념들을 만나게 됩니다.
확률분포, 모수(parameter), 회귀(regression) ...
변수(variable), 객체(object), 인자(argument), 매개변수(parameter) ...
어딘가 익숙한 말들인데 왜인지 낯설고 어려워 보입니다.
하지만 아무것도 중요하지 않습니다! 처음부터 용어 하나하나의 의미를 뜯어볼 필요가 없습니다. 낯선 개념을 완전히 이해하려고 하지 않아도 됩니다. 중요한 건 "기능"입니다. 기능을 직관적으로 받아들이고, 넘어가면 됩니다.
왜 제목이 "ActivePy"일까요? 무슨 뜻일까요? 이런 이름이어야만 했을까요? 아뇨, 중요하지 않습니다. 강연의 기능이 중요할 뿐입니다. 기능을 직관적으로 받아들이고 넘어가기: 항상 명심합시다.
그럼 ActivePython을 시작해봅시다.
Python for Text Data Analysis
"혼란스러운 세상, 데이터로 (비판적으로) 이해하기"
데이터를 근거로 세계를 비판적으로 독해하고 분석할 수 없다면, 우리는 주어진 정보를 무비판적으로 수용하거나 관성을 쫓아 판단하게 됩니다. 결국 문제의 원인을 제대로 분석하고 토론하기 어려워지고, 서로 대화불가능한 진단에 갇힌 채 실질적인 해결책을 모색하지는 못하게 됩니다.
한국사회는 불평등해지고 있는가?
예컨대 한국 사회에서는 "불평등과 양극화가 심화"되고 있다는 비판, 그리고 "사회적 이동성이 저하"되고 있다는 우려가 언론을 비롯한 곳곳에서 사용됩니다. 하지만 통계청 가계동향조사, 가계금융복지조사 등 실제 데이터에 근거한 실증 연구들은 조금 다른 사실을 보여줍니다. 예컨대 최근 한국사회 경제적 불평등이 심화 추세에 있지 않다고 지적하기도 하고[참고],
사회적 이동성이 다른 나라에 비해 낮거나 또는 낮아졌다고 단정하기 어렵다고 주장하기도 합니다.
물론 그렇다고 해서 불평등과 이동성 문제가 존재하지 않는다고 단정할 수도 없습니다. 다만 데이터의 전반적인 추세가 악화되는 방향을 가리키고 있지 않는데도 관성적인 구호와 지레짐작식의 진단만 반복한다면, 실제 문제에 대한 적확한 진단도 어렵고 그에 따른 쓸모있는 해결책의 제시도 어려울 것입니다. 대신 예컨대 소득/자산 분야에 따른 차이, 그리고 계층/지역/세대 등의 교차에 따른 양상을 살펴본다면 보다 세밀하고 다양한 결과를 도출할 수 있고, 그에 따른 새로운 문제 설정과 해결책을 고민해볼 수 있을 것입니다.
권위주의 국가는 무엇을 검열하는가?
또 하나의 예시를 살펴봅시다. 정치학자인 Gary King과 동료들은 2013년 중국의 인터넷 검열에 대한 논문을 발표합니다.
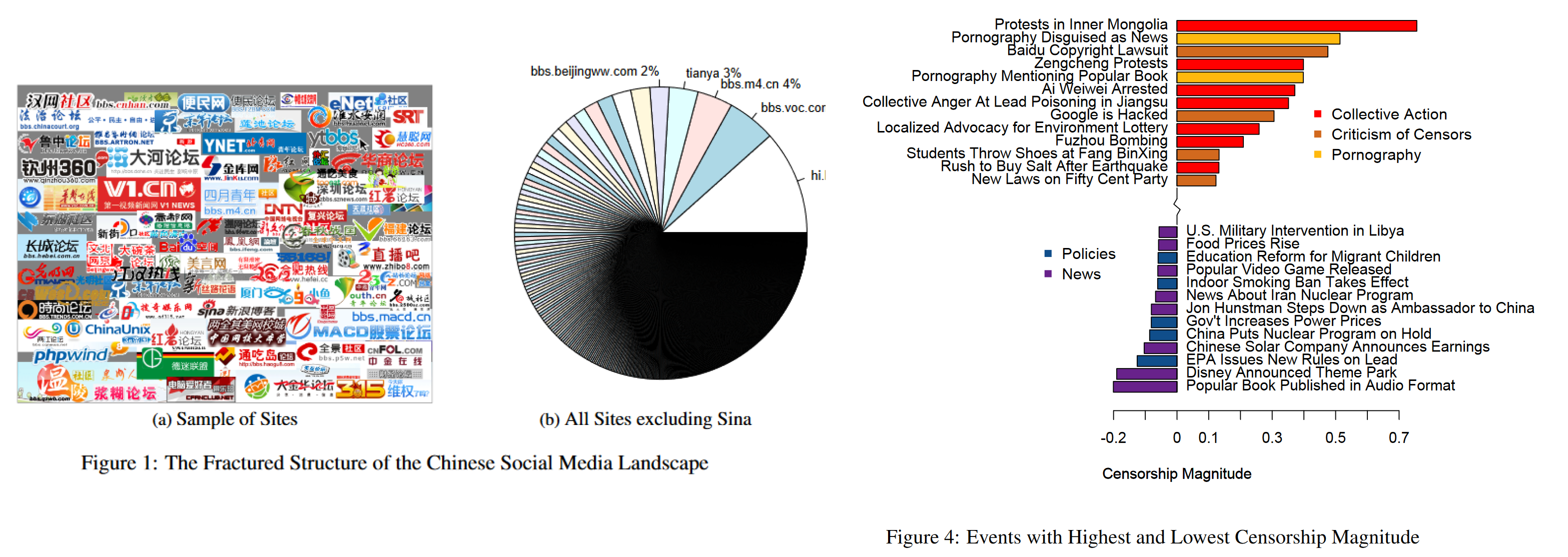
Fig1(p.329) & Fig4(p.334) from G., Pan, J., & Roberts, M. E. (2013)
저자들은 천여 개가 넘는 중국의 인터넷 사이트에 올라오는 게시글들을 실시간으로 크롤링하고, 이 글들의 검열 여부를 추적했습니다. 논문에 따르면 2011년 상반기 동안 3백6십만 개가 넘는 게시글을 수집하였고, 각 게시물들을 총 85개의 토픽으로 (머신러닝이 아닌 직접!) 분류했습니다. 토픽에 따른 검열 여부를 분석한 저자들은 일반적 생각과는 조금 다른 결과를 내놓습니다: 게시글의 내용이 얼마나 정치적으로 민감한지 보다도, 집단 행동을 조장할 우려가 있는지가 검열 여부와 더 밀접하게 관련되어 있었다는 것입니다.
이처럼 직접 대규모 데이터를 수집해 분석함으로써, 권위주의 국가 내에서 정치적, 문화적 검열이 이뤄지는 방식에 대해 지나치게 일반적이거나 과장된 추정이 아닌 보다 객관적인 분석을 제시할 수 있었습니다. 물론 당시의 상황은 현재와 또 많이 다르겠지요.
이런 사례들에서 볼 수 있듯, 데이터 분석은 반드시 어떤 하나의 일반적인 사실이나 절대적인 정답을 도출하는 과정은 아닙니다. 그보다는 겉으로 나타나는 사실 이면의 보다 복잡하고 다양한 양상을 찾아가는 과정입니다. 또한 데이터 분석은 자신의 주장을 강화하고 반대 의견을 일방적으로 반박해 가는 과정이 아니라, 기존의 상식을 비판적으로 성찰하면서 더 다양한 의견을 고려하고 이해할 수 있는 과정이기도 합니다.
Big Data
그런데 두번째 사례는 앞선 사례와 분석한 데이터의 성격이 꽤 다릅니다. 통계청에서 제공하는 가구 소득 데이터는 매우 잘 정제된 채 제공되는 데이터입니다. 반면 King과 동료들이 사용한 데이터는 인터넷으로부터 수집했고, 수집된 후 분석을 위해 - 불필요한 단어를 제외하고, 문장을 단어(토큰) 단위로 쪼개고 하는 식으로 - 열심히 가공(processing)한 데이터입니다. 그리고 당시 저자들이 토픽 모델링을 사용하진 않았지만, 요새는 이런 데이터에 토픽 모델링과 같은 머신러닝 기법을 많이 사용할 것입니다.
가구 소득 데이터가 보다 전통적인 데이터라면, King과 동료들이 수집해 사용한 데이터는 "빅데이터"라고 부를 수 있습니다. 인터넷이라는 비전통적인 출처로부터 수집되었고, 그 자체로 정제되어 있지 않은 "dirty"한 데이터이자 "텍스트"라는 비정형 데이터이기 때문에 많은 가공이 필요하며, 데이터를 잘 처리하고 분석하기 위해 전통적 통계적 방법뿐 아니라 머신러닝 등 새로운 분석 방법들이 많이 사용됩니다.
그리고 Big Data라는 이름답게 보통 데이터셋의 크기도 큽니다. 하지만 언제나 "Size matters"는 아닙니다. 통계청의 가구 소득 데이터도 회차마다 7천 또는 2만 개 가구를 조사하는 - 그 누적된 수를 생각해보면 더더욱 - 어마어마한 규모의 양질의 데이터입니다. 이런 전통적 데이터에 비해 빅데이터는 잘 정제되어 있지 않은 비정형성을 특질로 합니다.
잘 정제된 전통적인 데이터는 SAS, SPSS, STATA, R(?) 같은 전통적인 통계분석 소프트웨어를 이용해서 쉽게(?) 분석할 수 있었습니다. 하지만 "dirty"한 빅데이터를 처리하기 위해서는 R이나 Python 등 보다 사용자 제어도가 높은 프로그래밍 언어들이 사용됩니다. 또한 어떤 종류의 데이터든 빅데이터가 될 수 있지만, 텍스트 데이터가 포함되어 있는 경우가 많습니다. 사실 인터넷의 어딘가로부터 대규모로 수집된 텍스트 데이터야말로 빅데이터의 전형적인 사례일 것입니다.
왜 텍스트 데이터가 비정형 데이터의 대표적 사례일까요?
- 텍스트 데이터는 숫자와 달리 그 자체로 "단위"를 갖지 않습니다. 대체 어떤 단위로 텍스트를 분석해야 할까요? 형태소? 단어? 문장? 그렇다면 각 형태소/단어/문장은 서로 같은 규모를 갖나요?
- 텍스트 데이터는 그 자체로 "방향"과 "크기"를 갖지도 않습니다. 10과 20은 일관된 척도로 비교 가능하지만 "사과"와 "배"는 어떻게 비교해야 할까요?
- 그리고 10과 20은 겹치지 않지만, "배🍐"와 "배🚢"는 겹칩니다!
텍스트 데이터처럼 비정형성이 높아 많은 가공이 필요한 데이터를 다루기 위해 가장 애용되는 툴이 바로 Python입니다. Python은 그 자체로 프로그래밍 언어이기 때문에 사용자 제어도가 높고, 이런 유연성 덕분에 까다로운 데이터도 원하는 방향으로 효과적으로 처리할 수 있습니다. 또한 수많은 머신러닝/딥러닝 툴이 Python으로 배포되기 때문에, 머신러닝/딥러닝을 사용하기도 좋습니다. (딥러닝을 위해선 사실상 Python을 사용해야만 합니다.)
이번 강연에서 우리는 "텍스트 데이터 분석"에 집중할 것입니다. 넘쳐나는 혼란스러운 텍스트 데이터로부터 "구조"를 찾고, 그 구조를 표현하는 방법을 배울 것입니다. 날 것의 텍스트 데이터를 가공하는 방법(전처리; Preprocessing), 텍스트 뭉치로부터 의미 구조의 네트워크를 생성하는 방법(의미연결망 분석; Semantic Network Analysis), 문서 더미로부터 토픽 분포를 추출하는 방법(Topic Modeling), 그리고 마치 "벡터 공간"과 같은 의미 구조 속에서 각 단어들의 위치와 상대적인 거리를 표현하는 방법(Word Embeddings)을 배울 것입니다. 어쩌면 이 모든 것들이 최종적으로 Chat GPT같은 딥러닝과 어떻게 연결되는지까지 살펴볼 수 있을 것입니다.
그리고 이 모든 것을 위해 당연하게도(!) Python을 사용할 것입니다. 각각의 과정을 (어쩌면 더 잘) 수행할 수 있는 다른 툴들이 존재할지 모르지만, 이 모든 과정을 망라할 수 있는 툴은 역시 Python입니다. 본격적인 텍스트 데이터 분석에 들어가기 전에, 먼저 "데이터 분석"이 그래서 뭔지 조금 더 살펴보고, 또 "Revisit Python"이라고 이름 붙인 시간도 가져봅시다. 🔍